It would have been impossible to generate all of the manuscript using a single table such as Table 1, however. To account for the differences between sections, each manuscript section requires its own table, which could have been composed by tweaking entries in a previously produced table.
Measuring transition probabilities using the method described in Transition Probabilities, with the expanded state transition table (Table 1) as a template, on average resulted in a significantly higher error rate (ranging from slightly lower to more than double), so I decided to adjust the transition probabilities, by finding words generated more or less often using the state transition table than are present in the manuscript, and adjusting their transition counts downwards or upwards. This improved the results, but there were still some discrepancies. It might have been possible to improve the results further, e.g. by doing gradient descent in a multi-dimensional space (each dimension corresponding to a non-zero entry in the state transition table), but this would be very computationally intensive.
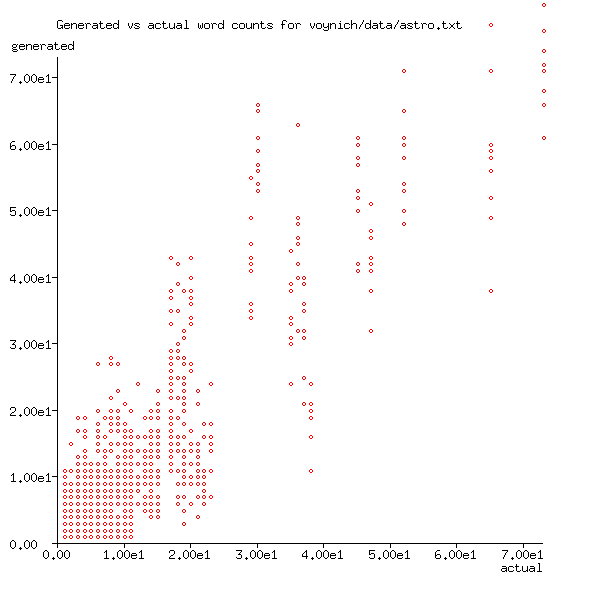
Figure 1 shows the word count for text, generated ten times using the state transition table for the red herbal pages (Currier B) of the manuscript (Table 2), plotted against actual word count in the Voynich Manuscript. Ideally, this should be a straight line of gradient 1.0, but with any process with an element of randomness will result in points being spread about that line. Here, there is an additional error caused by an imperfect state transition table. Similar plots for some other parts of the manuscript are shown in Figure 2, Figure 3, and Figure 4.

Figure 1: Generated vs actual word counts for red herbal pages