One of the most surprising things about the Voynich Manuscript is that the glyphs within words follow a clearly discernible grammar, yet the words in sentences don't. (In fact, as there's no punctuation, where sentences begin and end, or whether they exist at all, is unclear.)
All the prefixes in Table 1 and Table 2 in The Structure of the Words in the Voynich Manuscript can be generated by traversing this state transition diagram:
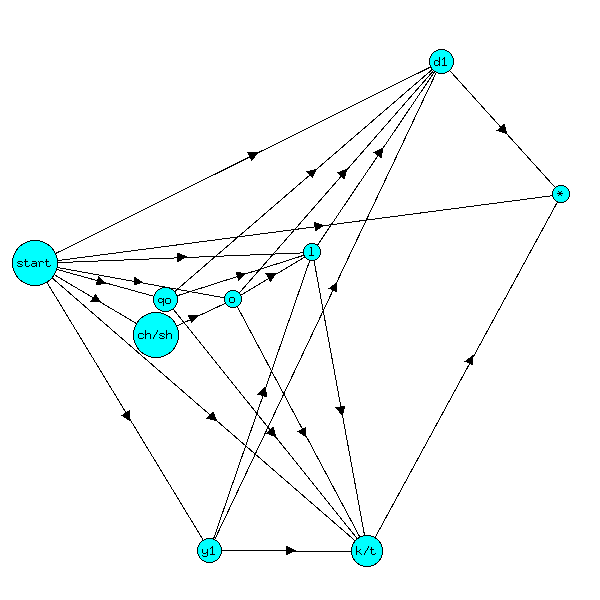
Figure 1: State transition diagram for common prefixes
All the suffixes in Table 2, Table 4, and Table 6 can be generated by traversing this one:

Figure 2: State transition diagram for common suffixes
NB * isn't really a state in either
diagram. Ideally, the two diagrams should be merged into a single diagram,
and any state in Figure 1 with a transition shown to *
has transitions to all of the states in Figure 2
with transitions shown from *.
q and o are normally considered
separate glyphs, but q is only very rarely followed
by anything other than o, so I have merged the two glyphs
into a single glyph, qo.
The diagrams are simplified in a number of ways. States
with the same precursor and successor states are merged, e.g.
k/t is really two states, k and t,
and a/o is a and o2. Numbered
states, e.g. y1 and y2, both output
the same letter but occur more than once. Finally, iX
indicates endings such as iin and ir.
For example, daiin can be generated
by traversing the states
start → d1 → a (one of a/o) → iin (one of iX) → finish
and qokeedy by traversing the states
start → qo → k (one of k/t) → e1 → e2 → d2 → y2 → finish
How it is decided which transition to taken from any state to the following one isn't at all obvious, but one possibility that should be considered is that it is random, possibly with different probabilities attached to each transition. This would mean that the text is meaningless, though it is possible that following a transition merely appears to be random, e.g. as a result of a previous encryption step, and it would be difficult to tell the two possibilities apart. However, it would render untenable the ideas that the manuscript is either plaintext in an unidentified language or non-verbose cyphertext.
Transition Probabilities
From any state, the transition probabilities can be reverse engineered by incrementing the count for the next transition leading to a state which writes the following glyph and then moving to that state, or backtracking (and decrementing the count) whenever no such state is found, and then following an alternative path from the last decision point. When this is repeated for the entire text, the probabity for a transition from a state are the number of times the transition has been traversed divided by the number of times any transition from that state has. As word frequencies vary throughout the manuscript, this will have to be done section by section.
For the blue herbal pages, the number of occurrences
of words with the common prefixes and suffixes is shown in Table 1.
Note that one word, dy, occurs twice, as -dy
and again as d-y.