Languages are written in various scripts with different glyph counts. Hawaiian has 13 letters, Chinese has thousands of characters. But Chinese characters represent whole syllables in spoken Chinese languages such as Mandarin, and sometimes several syllables in spoken Japanese. They also encode meaning, so different Chinese characters are often pronounced identically. Some other scripts (e.g. Hebrew and Arabic) omit vowels and so the same letter sequence can be pronounced in different ways.
Here, we'll mostly be examining text which is known
or assumed to be alphabetic and all the sound is encoded in the written
language. The choice of glyphs depends on the language and alphabet.
Most European languages are written in a modified Roman alphabet, and
for Latin, each letter mapped onto a single phoneme. In recent times,
this is no longer true, but it is still possible to map groups of letters
onto phonemes, fairly reliably in languages such as Italian, German,
and Hungarian, and not so well in English and French. In what follows,
a glyph is defined as comprising one or more letters corresponding to
a single phoneme most of the time, or a word boundary. Examples of
multi-letter glyphs include sch in German, gn
in Italian, th in English, and sz
in Hungarian.
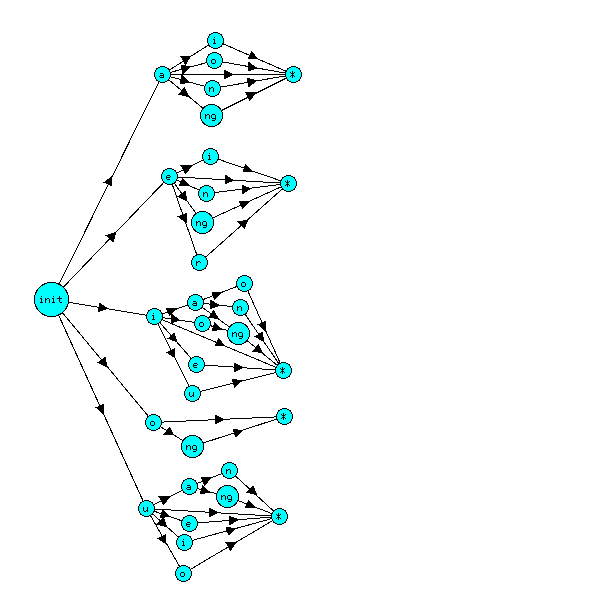
The probability of a particular glyph occurring in a given place depends upon its context, and in particular the glyph preceding it. If we know, for each glyph, how frequently each glyph that can follow it occurs, it might be possible to identify the language of a text automatically, and possibly also acquire information about the pronunciation of undeciphered scripts such as the Voynich Manuscript. (This doesn't imply its contents have any meaning, only that its creators had a particular pronunciation in mind.)
The approach I'm going to take is to represent each glyph by a vector whose components depend on the frequencies of the glyphs or word ending following it. These approximately follow a Zipfian distribution, so frequently occurring glyphs will dominate, and rarer glyphs will all have similarly low values whichever glyph they follow. As this effectively reduces the dimensionality of the space spanned by the vectors, and consequently the information content of the vectors themselves, I decided to use the log frequencies instead. The precise formula used is
a[b] = log(count(a b)) / log(count(a))
i.e. the component b of vector a is the logarithm
of the number of times a is followed by b, divided
by the number of times a occurs. The value of the
x-coordinate in the figures below is the position of b
in the glyphs which follow a after sorting them by increasing
frequency.
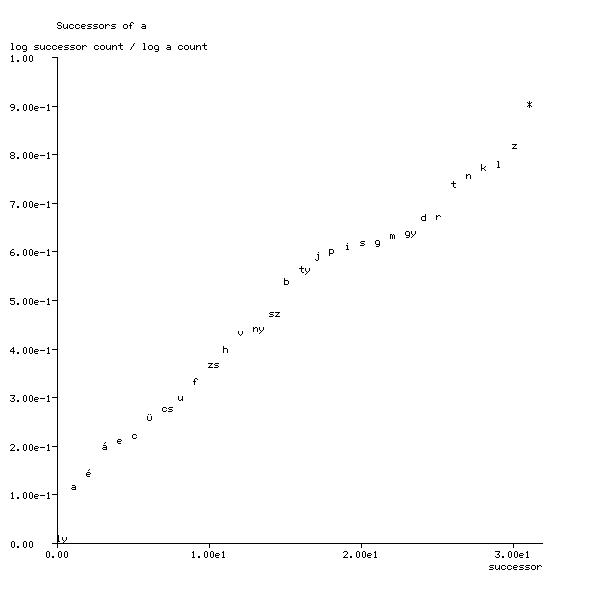
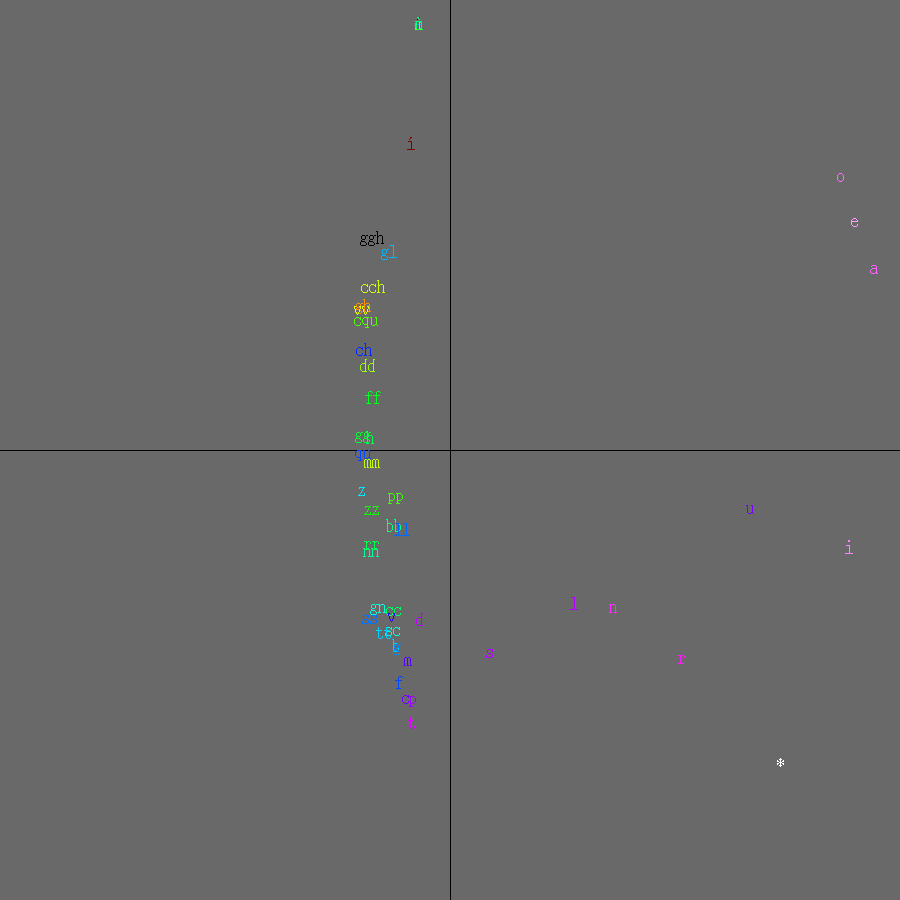
Figure 1: Successors of Hungarian a

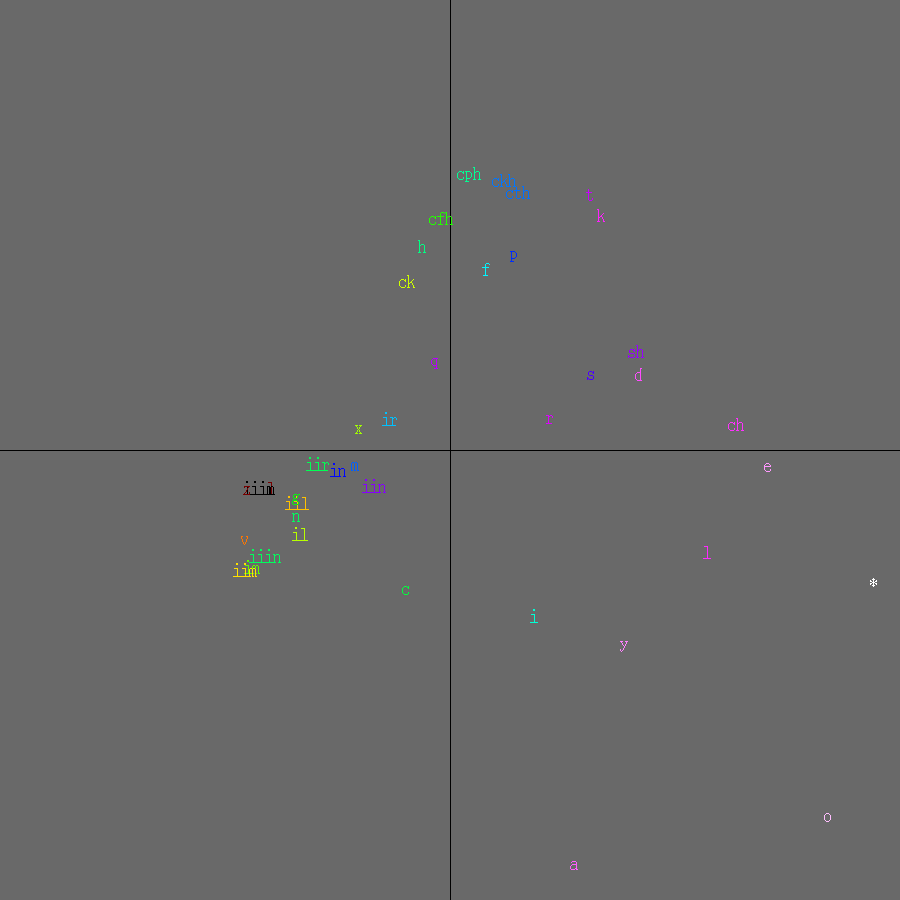
Figure 2: Successors of Hungarian f

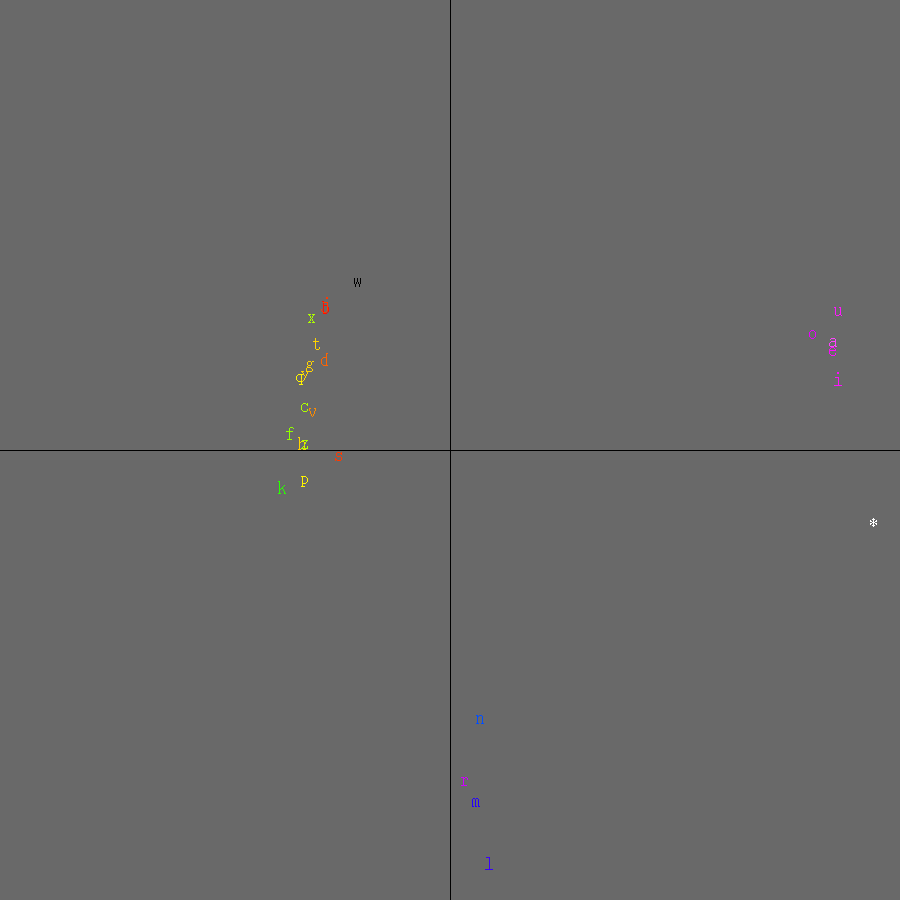
Figure 3: Successors of Hungarian sz
The plots in Figures 1-3 were made from the four
gospels in Gáspár Károli's
Hungarian
translation of the Bible published in 1590. * is used
for a word boundary. As can be seen, the plots are almost straight lines
through the origin. This results in more information about rarer glyphs
being retained. This is better for subsequent reduction to two dimensions
by Principal Component Analysis (PCA), as the glyph vectors will be more
evenly distributed in the glyph vector space.
The result of performing PCA on the text is shown in Figure 4: