Introduction
As far as I know, no one has discerned any sentence structure within the Voynich manuscript. I wanted to check whether the words in it were just randomly distributed, or there were any associations between them. This time, I applied principal component analysis to the words, using a method very similar to word2vec.
Results
Words in the manuscript were represented as
bags of neighbouring
words (five on either side, though the exact number isn't important). These
bags were converted to vectors, with the same words in each bag determining
the indices, and their multiplicities determining the index values.
For example, the bag ((a . 7) (b . 2) (c . 5) (d . 6)) with
bases #(a c d) becomes the vector #(7 5 6).
Principal component analysis was then performed on these vectors, firstly
for more common words (occurring 50-200 times), and then for rarer words
(occurring 20-50 times).
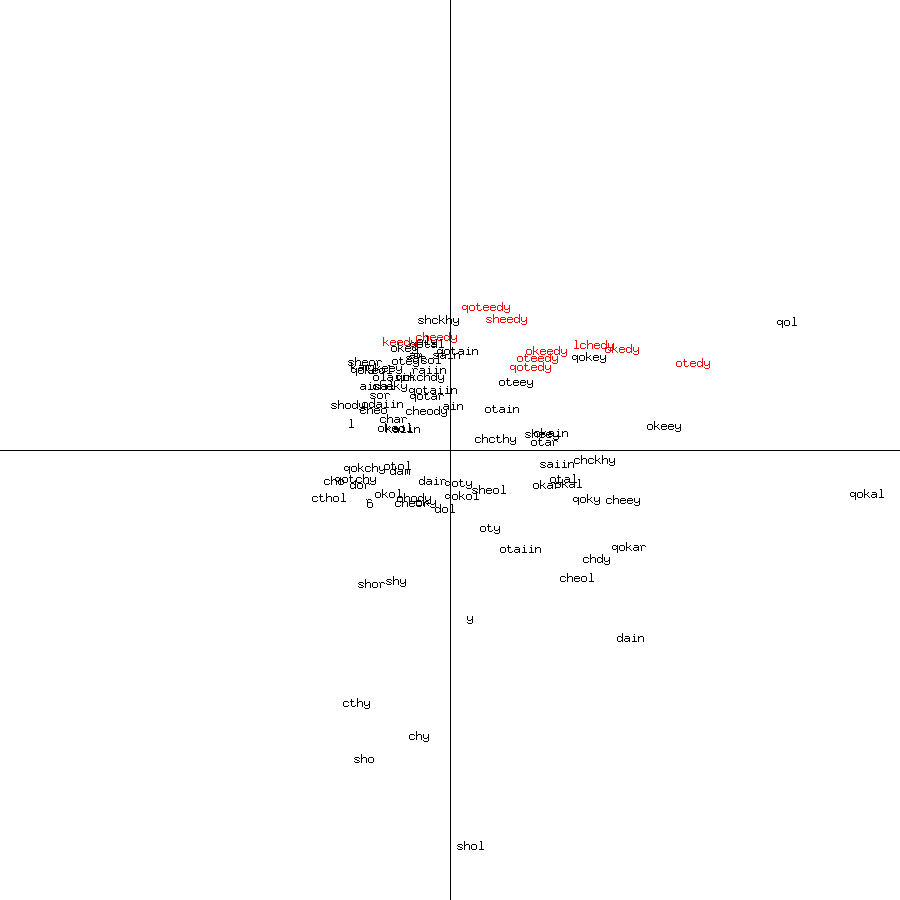
Figure 1: words occurring 50-200 times

Figure 2: words occurring 20-50 times
I noticed that words ending in
EVA edy
form a distinct cluster (shown in red) in both common and rare words.
An inspection of the text showed that some pages had numerous occurrences
and others had few or none, and that the first page with such words is f26r.
Those with many occurrences are Currier B pages, and those with none are
Currier A pages. The clustering is simply caused by the frequency within
different pages, rather than any sentence structure. It suggests, though,
that the Currier A/B division is significant after all.
Further analysis has shown that other words are common in Currier A pages and rare in Currier B pages, or vice-versa, so I examined their position on the word plots. This is best shown on the plot below, which uses two words on either side of each word for its bag.

Figure 3: words occurring 100 times or more
The words in red occur more frequently in Currier B pages, and those in blue in Currier A pages.
| Currier A words |
| daiin |
| chol |
| chor |
| cthy |
| s |
| sho |
| Currier B words |
| -edy |
| qokeey |
| qokey |
| qol |
| qokain |
| qokaiin |
| qokal |
| qokar |
| chey |
| shey |
These can be used to define a function of pages:
(count(Currier B words) - count(Currier A words)) / count(words)
which can be applied to the page PCA plot.

Figure 4: PCA plot of pages. Blue = Currier A, red = Currier B.
This shows that there is no clear dividing line between Currier A and B. The transition from A to B is gradual.
Conclusion
The position of a page on the PCA plot of pages is determined by the frequency of certain words within the page, but not apparently by their order.
© Copyright Donald Fisk 2017