Introduction
The Voynich Manuscript is an illustrated book written in an unidentified language in unknown script. More information on it can be found at Rene Zandbergen's site. Radiocarbon dating fixes its creation during the first half of the 15th century. Details of some of its illustrations tend to confirm this, and hint that its most likely origin is northern Italy, although this is by no means certain. Straightforward statistical analysis shows that the text possesses certain properties common to natural languages, e.g. the frequencies of glyphs and words closely follow Zipf's Law. Beyond this, very little is known about it.
A Statistical Approach
Many people have analysed the manuscript statistically, but with very limited success. For example, Prescott Currier reported in Papers on the Voynich Manuscript that the text is in two separate languages or dialects, now commonly referred to as Currier A and Currier B. It will be shown here that this distinction is somewhat fuzzy. There are differences (see A Principal Component Analysis of the Voynich Manuscript Words), but these can be explained more simply by differences in the text's subject matter.
Sarah Goslee carried out a similar PCA in 2006. Her results are in Voynich Manuscript - Basic Analyses.
The manuscript is divided up into different illustrated and non-illustrated sections. These are
- Herbal
- Cosmological
- Astronomical
- Astrological
- Biological (or Balneological)
- Pharmaceutical
- Recipes
- Text
NB: When the manuscript was created, there was a fine distinction between astronomy and astrology, and what is meant by cosmology here is unclear. The biological pages contain pictures of naked women in a series of tubes. (This sounds like a description of the Internet, but is highly unusual in mediaeval manuscripts. The only one I'm aware of bearing any resemblance is Petrus de Ebulo, De balneis puteolanis.) The recipes are simply text with some stars in the margin.
The text is in what appear to be words separated by spaces.
These words were first ordered by descending frequency, down to those
occurring only five times in the entire manuscript. Each word was
represented as a separate basis vector in a 960-dimensional space.
Each page was then converted to a vector in this space, with each
component being the ratio of the number of occurrences on the page
and the total number of words on the page. A
principal component analysis was then carried out on each page vector, reducing
each point in the 960-dimensional space down to the first two principal
components. One outlier, f65r, which contains only three words, in EVA:
otaim dam alam, was omitted. The results are plotted in
Figure 1.
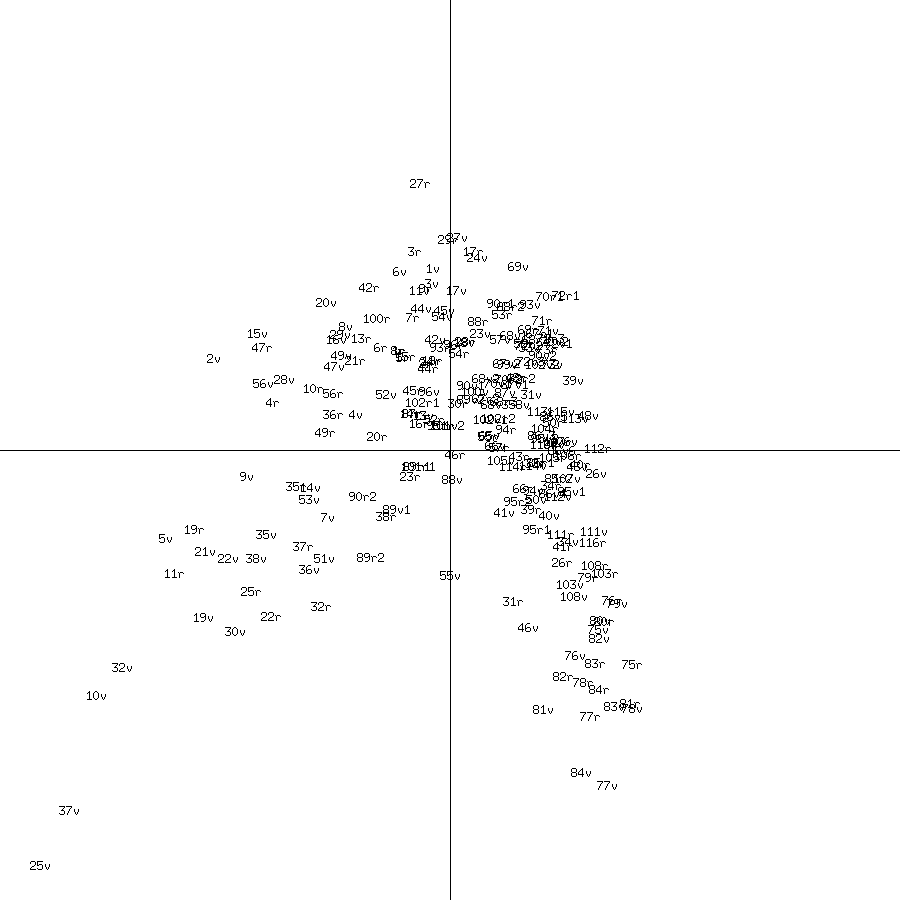
Figure 1: Plot of VM pages against first two principal components
There is a curve like an inverted V. There are no obvious clusters. When each page is labelled either Currier A (green), Currier B (red), or uncertain (black), it can be seen that the division between A and B is quite arbitrary (Figure 2). Sarah Goslee obtained a near identical plot in her Figure 2 in Voynich Manuscript - Basic Analyses. (The orientation of the axes makes no difference in PCA.)

Figure 2: Plot of VM pages by Currier A and B "languages" against first two principal components
Alternatively, pages can be labelled according to the section they belong to (Figure 3). Sarah Goslee obtained a near identical plot in Figure 4 in Voynich Manuscript - Basic Analyses.
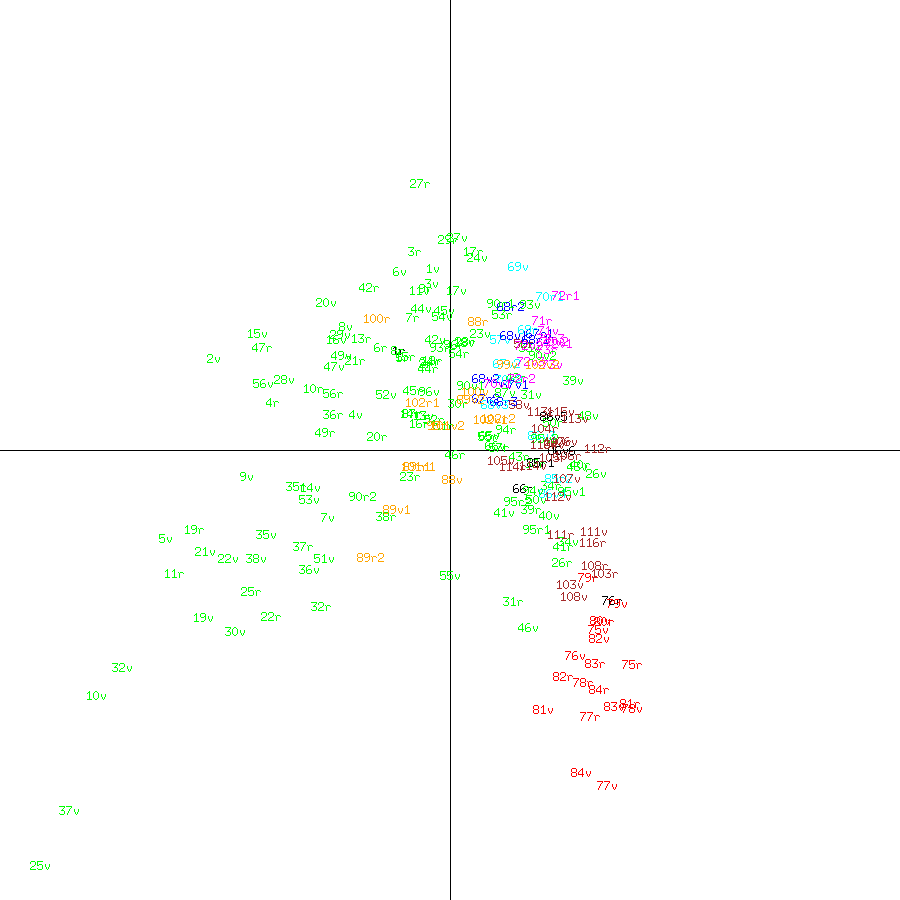
Figure 3: Plot of VM pages by section against first two principal components
In Figure 3, sections are color-coded as follows:
| Section | Color |
| Herbal | green |
| Cosmological | cyan |
| Astronomical | blue |
| Astrological | magenta |
| Biological | red |
| Pharmaceutical | orange |
| Recipes | brown |
| Text | black |
We can now see that each section is a cluster in its own right, but without gaps between them. The astronomical, astrological, and cosmological sections overlap, as do the recipes and text. The pharmaceutical pages are surrounded by herbal pages. The herbal pages occupy most of the inverted V, with lower right end containing a tight cluster containing the pages with naked women.
After merging the astronomical, astrological, and cosmological
sections; the herbal and pharmaceutical sections; and the recipe and text
sections, the plot becomes (Figure 4):

Figure 4: Plot of VM pages by merged section against first two principal components
Figure 4 strongly suggests that each section contains text on a single general topic with associated vocabulary, as we would expect if the text matches the illustrations. It also makes it less plausible that the text is meaningless.
We can confirm that different topics result in different clusters with known content. To do this, I assembled a surrogate Voynich Manuscript in Latin from several books of Natural History by Pliny the Elder (English translation). Given the presumed origin of the manuscript, the plaintext is most likely German, Latin, or Italian, though other European languages cannot be ruled out. The color coding is:
| Book | Topics | Color |
| Liber II | astronomy and meteorology | black |
| Liber VII | anthropology and physiology | red |
| Liber XXV | herbs | green |
| Liber XXVI | herbs | cyan |
| Liber XXVII | herbs | blue |
| Liber XXXIII | metals | magenta |
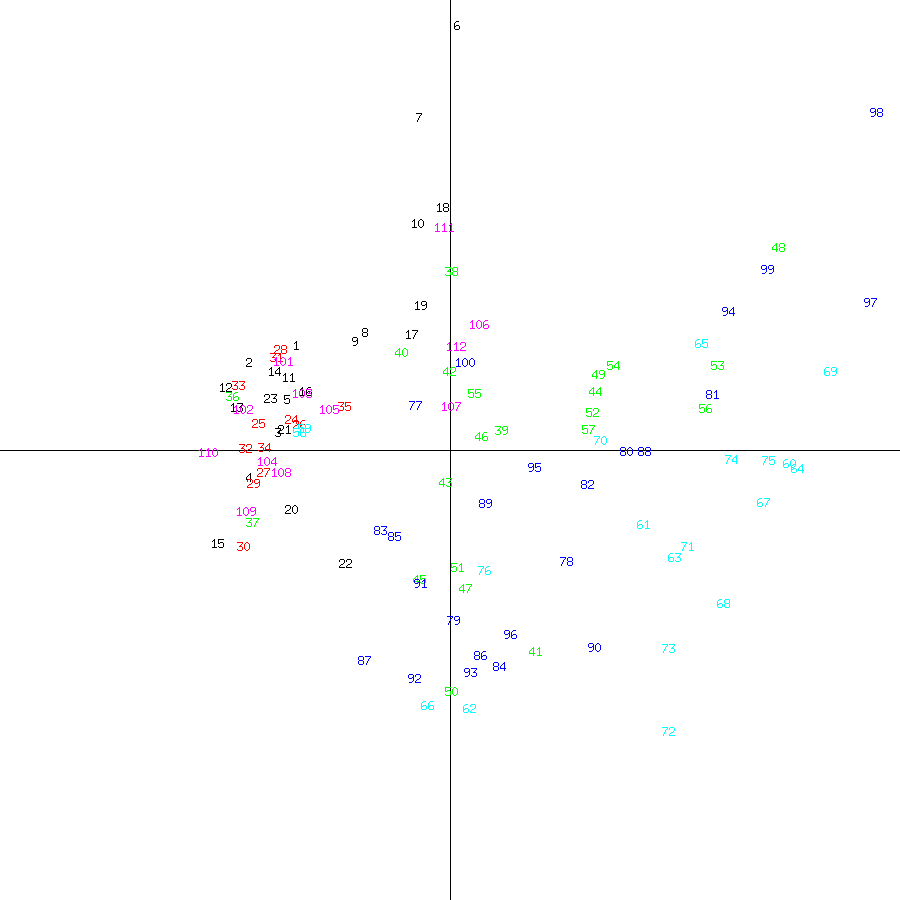
Figure 5: Plot of Pliny pages by section against first two principal components
Again, the pages (each of which contains six of Pliny's short chapters) of each book are clustered by topic.
Conclusion
The results are consistent with the text of the Voynich Manuscript containing meaningful information, as the text correlates more closely with the illustrations than would be expected by chance. This suggests, but doesn't prove, that the herbal pages are about herbs, the astrology pages are about horoscopes, and so on.
If the pages are meaningless, its author would have had to vary the method used to generate the pages according to the subjects of the illustrations.
© Copyright Donald Fisk 2017